
在说分类器前我们先了解一下线性分类
线性函数y = kx + b ,在对于多种类别、多个特征时可将W看做一个矩阵,纵向表示类别,横向表示特征值,现在有3个类别,每个类别只有2个特征

线性分类函数可定义为:
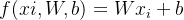
我们的目标就是通过训练集数据学习参数W,b。一旦学习完成就可以丢弃训练集,只保留学习到的参数。
1. 损失函数
损失函数是用来告诉我们当前分类器性能好坏的评价函数,是用于指导分类器权重调整的指导性函数,通过该函数可以知道该如何改进权重系数。通俗都来说一组参数(W,b)对应一个损失L,一般的损失越小模型越好,我们目标是通过各种优化,使损失达到最优值(不一定最小是最优的)。
常见的损失函数:
对数似然损失
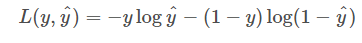
百页损失
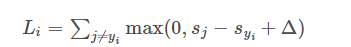
现在通过百叶损失对前面线性分类求损失:
2. Softmax分类器与交叉熵损失(cross-entropy)
Softmax
函数定义:
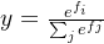
简单的说,softmax函数会将输出结果缩小到0到1的一个值,并且所有值相加为1
使用softmax函数对前面线性分类求得分
类别1 :
类别2 :
类别3 :
交叉熵损失(cross-entropy)
交叉熵损失衡量分类模型的性能,其输出是介于 0 和 1 之间的概率值。交叉熵损失随着预测概率与实际标签的偏离而增加。因此,当实际观察标签为 1 时预测 0.012 的概率模型不好,并导致高损失值。完美模型的对数损失为 0。cross-entropy一般再softmax函数求得结果后再用,
函数定义:
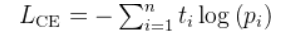
是真实值,是softmax函数求得的结果。
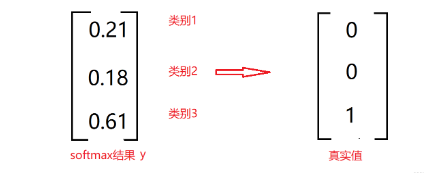
因为真实值只有属于这个类别或者不属于这个类别,1代表是这个类别,如图所示表示改输入是类别3,
cross-entropy计算
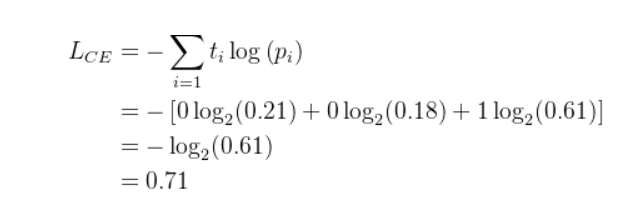
为什么要加负号?
log函数图像:
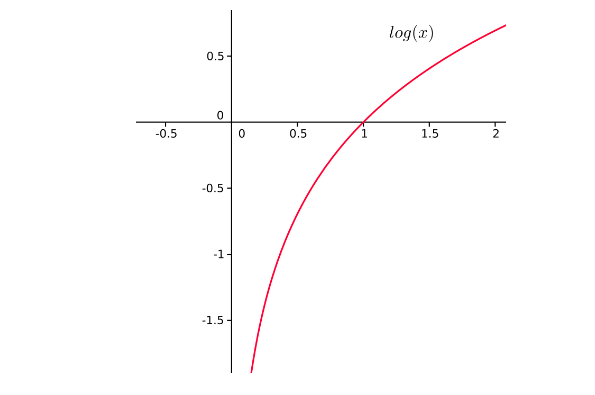
因为softmax求出结果再(0,1)之间,所以cross-entropy结果为负值,加负号使得损失为正。
假如现在通过优化使得softmax 后结果为0.10、0.08、0.82,再计算cross-entropy结果对比一下

0.28小于之前的损失0.71,暗示模型正在学习。优化过程(调整权重以使输出接近真实值)一直持续到训练结束